Action Prediction
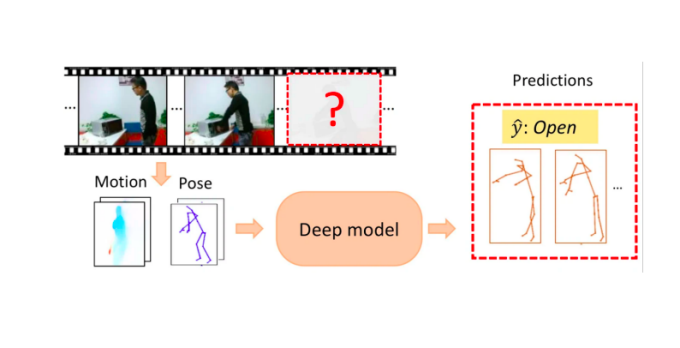

Anticipating human actions addresses the problem of predicting what a person is going to do next and how they will perform it. In this project, we try to jointly predict human action categories and skeleton pose joints.
Overview
It is clear that after gaining experience, humans have the ability to anticipate future unseen events in a continuous space-time action space. For example, in the above figure, one can immediately infer that the subject action is about to open the microwave and also imagine the successive human pose of reaching his arms forward. Our ability to anticipate such actions and events help us to effectively adapt to changing environments and helps us interact with each other. It is then reasonable to expect that we should attempt to incorporate such capabilities into the design of intelligent systems. Methods can be developed to analyse a sequence of steps and make predictions of future behaviors from stream videos.
In this project, we address the problem of joint human action and pose anticipation, where a pose is defined by a set of body joints in future video frames based on available observations at the current time. Specifically, we focus on the skeleton pose that typically uses 14 or 25 joint points to represent a body position. After extracting joint points from an image we can use them to model the human dynamics. we model this task as a multi-task learning problem, including action category classification and skeleton joints prediction. Given a video stream, motion features (optical flow) and poses are extracted for every frame. Then at every time step, they are fed into a encoder-decoder recurrent network, a sequence-to-sequence model, to predict a sequence of future actions and poses progressively.